Jeśli planujesz stworzyć mniej rozbudowaną stronę, która nie zawiera wielu elementów dynamicznych (czy to po stronie serwera czy na frontendzie) i posiadasz pewną wiedzę techniczną, to do jej stworzenia możesz wykorzystać Jekylla – generator statycznych stron.
Podstawową zaletą użycia generatora będzie uzyskanie plików statycznych, które mogą być bez problemu udostępniane przez każdy serwer HTTP. Rozwiązanie takie będzie działało znacznie szybciej, niż w przypadku stron generowanych dynamicznie przez WordPressa (czy przez jakikolwiek inny CMS).
Do kogo kierowany jest ten poradnik?
Omawiane zagadnienia wymagają:
- umiejętności pracy z plikami tekstowymi oraz z katalogami;
- podstaw HTMLa (przydatne może być też rozumienie Markdown czy innych systemów szablonów tekstowych często wykorzystywanych właśnie do generowania treści w HTMLu);
- umiejętności pracy z oprogramowaniem uruchamianym z terminala tekstowego.
Czego potrzebujesz?
- zainstalowanego Dockera,
- terminala tekstowego,
- edytora tekstu (względnie innego oprogramowania do edycji plików tekstowych).
Czego się nauczysz?
Korzystając z niniejszego poradnika dowiesz się, jak:
- zainstalować obraz Dockera zawierający Jekylla,
- wykorzystać ten obraz do uruchamiania Jekylla,
- przy pomocy Jekylla wygenerować statyczne dokumenty korzystając z gotowego szablonu HTML/CSS,
- tworzyć w Liquidzie szablony dla statycznych stron.
Wiedza ta będzie zaprezentowana na prostym przykładzie, który możesz rozwijać dalej już we własnym zakresie.
Krok 1 – instalacja oprogramowania
Jekyll jest najstarszym z dostępnych generatorów stron statycznych. W związku z tym można znaleźć wiele tekstów opisujących proces instalacji. Bez problemu znajdziesz je również na oficjalnej stronie Jekylla w dokumentacji.
Większość tych opisów (włącznie z oficjalnym) jest identyczna. Z jednej strony, trudno się temu dziwić wszak, na ile sposobów można zainstalować tę samą aplikację? Z drugiej strony, gdy ktoś, kto nie zna języka Ruby (w którym jest napisany Jekyll) i nigdy tego środowiska nie używał, zobaczy prostą instrukcję zawierającą następujące polecenie:
$ gem install bundler jekyll… może poczuć się nieswojo. Wynika z tego, że aby używać Jekylla, konieczna jest instalacja dodatkowego oprogramowania (owego gema), a kto wie, co jeszcze będzie potrzebne?
Tymczasem, używając Dockera, możesz uruchomić aplikację w kontenerze. W repozytorium hub.docker.com dostępne są gotowe obrazy (w tym oficjalne dostarczone przez twórców Jekylla). W takiej sytuacji wystarczy po prostu, że pobierzesz odpowiedni obraz z repozytorium:
$ docker pull jekyll/jekyll:minimalW dalszej części niniejszego artykułu, skupisz się na wykorzystaniu obrazu Dockera do pracy Jekyllem. Myślę, że warto pokazać tę metodę, gdyż praca z Jekyllem z poziomu systemu operacyjnego (a więc wymagająca instalacji środowiska języka Ruby) jest już dokładnie opisana w oficjalnej dokumentacji Jekylla oraz w wielu innych tekstach. Nie ma powodu, żeby powielać te informacje. Poza tym zapewne jest więcej użytkowników Dockera niż użytkowników Ruby.
Mając już obraz Jekylla, możesz go teraz wykorzystać do pracy z aplikacją w następujący sposób:
$ docker run --rm -it -v "$(pwd):/srv/jekyll" -p 4000:4000 jekyll/jekyll /bin/bashPolecenie to powinno być zrozumiałe dla użytkowników Dockera, niemniej warto dokładniej je opisać dla tych użytkowników, którzy dopiero zaczynają przygodę z tym oprogramowaniem:
- opcja -v “$(pwd):/srv/jekyll” powoduje podmontowanie aktualnego katalogu roboczego (ang. current working directory) w katalogu /srv/jekyll obrazu Dockera. Dzięki temu Jekyll uruchamiany w kontenerze będzie miał dostęp do plików na lokalnym dysku. Pozwoli Ci to na edytowanie tych plików na swoim komputerze za pomocą dowolnego edytora tekstu, a następnie przetwarzanie ich za pomocą Jekylla.
- opcja -p 4000:4000 „wiąże” ze sobą porty 4000 w systemie operacyjnym i w kontenerze Dockera. Jest to bardzo przydatne, gdyż Jekyll ma wbudowany serwer HTTP, który pozwala na sprawdzenie wygenerowanej strony w przeglądarce. Serwer ten działa domyślnie właśnie na porcie 4000.
- wreszcie /bin/bash jest poleceniem, które zostanie wykorzystane do uruchomienia procesu w kontenerze. Jest to zwyczajna powłoka systemowa, z której uruchomisz Jekylla.
Aby sprawdzić, czy wszystko działa poprawnie, możesz wydać polecenie (naturalnie w uruchomionym już kontenerze Dockera):
bash-5.0# jekyll --helpKrok 2 – przygotowanie szablonu HTML/CSS
Ponieważ nie jestem specjalistą od CSS (ani nawet od HTMLa), skorzystam z gotowego, darmowego szablonu, który można znaleźć „w sieci”. Będzie to Purple Buzz. Rzecz jasna, korzystając z Jekylla możesz wykonać stronę w oparciu o dowolny szablon.
Purple Buzz jest dość rozbudowany, co pozwala na wykonanie złożonej strony z wieloma podstronami. Niemniej w niniejszym poradniku skupisz się na stronie głównej oraz jednej podstronie. W zupełności wystarczy to do prezentacji (oraz nauki) podstawowych funkcji Jekylla. Ewentualną rozbudowę strony możesz potraktować jako zadanie do samodzielnego wykonania.
Gotowy szablon składa się z kilku plików .html oraz katalogu assets, w którym znajdują się pliki .css, .js, obrazy oraz czcionki wykorzystywane w dokumentach. Tak jak wspomniałem, w niniejszym poradniku skupisz się na dwóch stronach: stronie głównej (plik index.html) oraz jednej podstronie (plik work-single.html).
W Jekyllu stosowany jest tzw. Liquid. Jest to silnik szablonów, który bazuje na konkretnych szablonach, fragmentach (ang. includes) oraz zmiennych. Szablon stanowi szkielet dokumentu. Możesz w nim wykorzystać fragmenty, które są zapisane w odrębnych plikach. Zmienne są zazwyczaj definiowane w konkretnych dokumentach.
Praca z Jekyllem polega w zasadzie na zapisaniu szablonu HTML/CSS (np. takiego, jak przykładowy Purple Buzz) w postaci powtarzalnych szablonów oraz również powtarzalnych fragmentów. Co prawda Jekyll może wygenerować dokument, który nie wykorzystuje żadnego szablonu, w praktyce jest to jednak rzadko stosowane. Główną zaletą używania Jekylla (jak również innych generatorów statycznych stron) jest stosowanie szablonów, które uzupełnione odpowiednią treścią, dają w efekcie konkretne strony.
Krok 3 – stworzenie strony głównej
Zacznij od wykonania strony głównej.
Ponieważ nie masz jeszcze niczego, poza szablonem HTML/CSS, pracę rozpocznij od utworzenia katalogu na projekt.
Na początek warto zrobić coś naprawdę prostego: wstaw dokument index.html, wzięty wprost z szablonu HTML/CSS i sprawdź, jaki będzie efekt pracy Jekylla. Plik umieść w katalogu projektu, po czym uruchom Jekylla:
bash-5.0# jekyll buildJekyll działa w bardzo prosty sposób: odnajduje wszystkie pliki w katalogu projektu i odpowiednio je przetwarza, jeśli jest taka potrzeba.
Dokładniej to ujmując, Jekyll odnajduje wszystkie pliki z pominięciem pewnych katalogów. Jakie to katalogi? Między innymi _layouts (zawierający szablony), _includes (zawierający fragmenty dokumentów) czy assets (zawierający pliki, które również powinny należeć do strony, a nie są przetwarzane przez Jekylla, jak np. arkusze stylów czy skrypty JavaScript).
Efektem działania polecenia są pliki zapisane w katalogu _site. Co się tam znajduje? Skopiowany plik .html, który Jekyll znalazł w głównym katalogu. Zawartość tego pliku możesz sprawdzić, otwierając go w przeglądarce albo w edytorze tekstu.
Wyglądem dokumentu w przeglądarce zajmiesz się za chwilę. Najpierw warto skomentować pewien fakt: plik index.html w katalogu _sites jest po prostu kopią pliku index.html z katalogu głównego projektu. Wygląda na to, że Jekyll po prostu utworzył katalog _sites, a następnie skopiował tam plik index.html.
Jekyll działa właśnie w taki sposób. Jeśli w danym pliku .html nie zaznaczysz, że ma on zostać odpowiednio przetworzony przez Jekylla, to plik zostanie po prostu skopiowany do katalogu _sites (w odpowiednie miejsce, z uwzględnieniem struktury katalogów w katalogu głównym projektu) bez żadnych zmian.
Rzecz jasna, nie po to używasz Jekylla, żeby kopiować pliki. Aby włączyć wspomniane przetwarzanie, musisz dodać do pliku odpowiedni nagłówek. Tym zajmiesz się za chwilę, bowiem wcześniej trzeba rozwiązać inny problem: strona nie wygląda tak, jak powinna:

Co się stało? Doświadczenie może podpowiedzieć Ci, że zapewne niektóre arkusze stylów CSS nie zostały załadowane. Możesz to sprawdzić w konsoli przeglądarki:
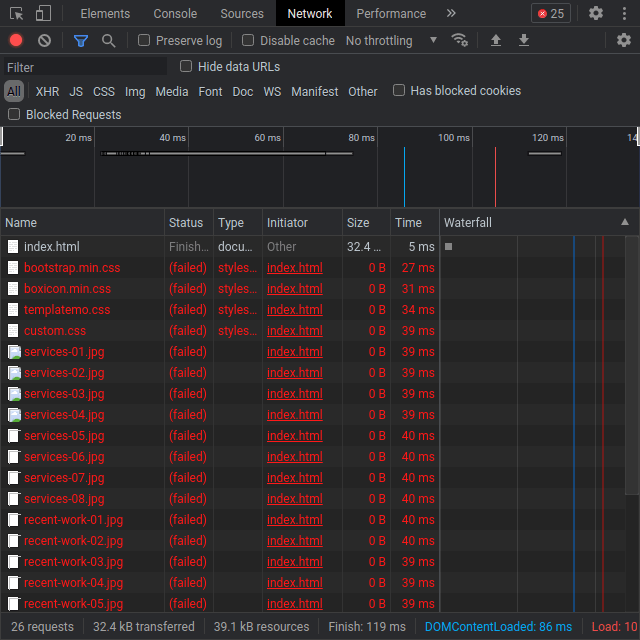
Jak widzisz, podejrzenie było słuszne! Dokument index.html odwołuje się do pewnych plików (.css, .jpg i .js), które nie zostały znalezione i wczytane. Aby ten problem rozwiązać, musisz:
- Skopiować brakujące pliki z szablonu do katalogu assets w projekcie.
- Upewnić się, że ścieżka dostępu do tych plików jest poprawna w dokumencie index.html.
W przypadku używanego szablonu powinno wystarczyć umieszczenie katalogu assets z szablonu w katalogu projektu. Po wykonaniu tych czynności ponownie zbuduj stronę:
bash-5.0# jekyll build… i „odśwież” ją w przeglądarce. Końcowy efekt powinien być taki sam, jak w oryginalnym szablonie.
Krok 4 – wyodrębnienie szablonu
Skoro sprawa z brakującymi plikami została rozwiązana, pora zabrać się za kolejny problem: nie będziesz przecież używać Jekylla do zwykłego kopiowania plików.
Jak zostało już napisane, Jekyll działa na bardzo prostej zasadzie: na podstawie szablonu oraz pewnych danych (np. treści dokumentu) może wygenerować dokument HTML. W tym przypadku potrzebujesz po prostu szablonu.
Zasadnicze pytanie brzmi: jaka część dokumentu index.html powinna stanowić szablon (ang. layout), a jaka część treść? Z definicji tych pojęć wynika, że szablon powinien być stały, natomiast treść może się zmieniać. Gdyby to był rzeczywisty projekt, to właśnie nad takimi problemami należałoby się zastanowić. Na potrzeby niniejszego tekstu przyjmij, że na stronie głównej nie będzie treści, a jedynie szablon.
Najprościej będzie, gdy skopiujesz plik index.html do katalogu _layouts (katalog taki trzeba uprzednio utworzyć), jako np. home.html. Następnie całą zawartość pliku index.html w katalogu głównym projektu podmień na następującą:
---
layout: home
---Po ponownym uruchomieniu Jekylla i sprawdzeniu wyników powinno się okazać, że strona wciąż wygląda tak samo. To dobrze – nie powinno być żadnych zmian. Warto jednak zwrócić uwagę na dwie sprawy.
Po pierwsze, zawartość pliku index.html uległa zmianie. Część pomiędzy wierszami zawierającymi po trzy znaki „-”, to tzw. część początkowa (ang. Front Matter). Zamieszczane są tam informacje w formacie YAML opisujące dane dotyczące generowanej strony. W tym przypadku jest to tylko jedna informacja dotycząca szablonu. Dzięki tej informacji Jekyll użyje pliku home.html z katalogu _layouts.
Ewentualna treść strony mogłaby zostać umieszczona właśnie po części początkowej. Jak jednak zostało już wspomniane, tworzysz tylko szablon, bez treści.
Po drugie, praca z Jekyllem zaczyna być nieco męcząca. Po każdej zmianie musisz wydawać to samo polecenie służące do wygenerowania strony. Byłoby prościej, gdyby Jekyll wykrył, że zawartość plików została zmieniona, a następnie automatycznie wygenerował stronę. Efekt taki możesz uzyskać, używając polecenia:
bash-5.0# jekyll serveStrona nie tylko będzie wygenerowana, ale również zostanie uruchomiony serwer HTTP na porcie 4000. Jeśli w przeglądarce wpiszesz adres http://localhost:4000, to zobaczysz zawartość wygenerowanego pliku index.html z katalogu _site.
Niezależnie od tego, czy tworzysz strony w WordPressie czy też korzystasz ze statycznych generatorów stron takich jak opisywany tu Jekyll, Elastyczny Web Hosting sprawdzi się w każdej sytuacji!
Wysokie parametry gwarantowane (1 GHz CPU, 2 GB RAM oraz 50 GB SSD NVMe) sprostają zapotrzebowaniu większości stron WWW. Ponadto jeśli w którymkolwiek momencie będziesz potrzebować więcej zasobów, zostaną Ci one przydzielone automatycznie.
Skorzystaj z 14-dniowego okresu testowego i sprawdź w praktyce możliwości EWH.
Krok 5 – tworzenie fragmentów szablonu
Spróbuj teraz nieco ulepszyć szablon, wydzielając część nagłówka do osobnego pliku. Nagłówek można bez problemu wyszukać w pliku home.html. Jest wyraźnie zaznaczony odpowiednim komentarzem. Całą tę część nagłówka skopiuj do pliku header.html, a plik ten umieść w katalogu _includes (katalog musisz wcześniej utworzyć).
W katalogu _includes znajdują się pliki z różną treścią, które można włączać do szablonów. Taki nagłówek może być wykorzystany na różnych stronach, a więc warto go wydzielić do osobnego pliku. Przy okazji możesz wstawić nazwę firmy zamiast „Purple Buzz” oraz usunąć te elementy, które nie będą wykorzystane. W Twoim przypadku będą to odnośniki do innych stron, ukryte pod ikonami z prawej strony nagłówka.
Aby wykorzystać plik z katalogu _includes w szablonie, użyj polecenia:
{% include header.html %}Polecenie to powinno zastąpić całą treść nagłówka w pliku home.html.
Krok 6 – tworzenie i wykorzystywanie danych (kolekcji)
Wykorzystanie fragmentów w szablonach to nie koniec możliwości silnika Liquid używanego przez Jekylla. Spróbuj zastąpić menu, widoczne w nagłówku, poprzez dane.
Czym są dane? W Jekyllu możesz zapisywać dane o różnych kolekcjach (uporządkowanych zbiorach) w plikach zamieszczanych w katalogu _data, w formacie YAML. Wykorzystaj tę funkcjonalność do uproszczenia procesu zarządzania menu w nagłówku.
Każda pozycja menu posiada swoją nazwę oraz URL, czyli adres. Utwórz więc w katalogu _data plik top_menu.yaml o następującej treści:
- name: Nasza firma
url: /
- name: O nas
url: /about
- name: Kontakt
url: /contactAby wykorzystać te dane w pliku header.html, zastąp kod HTML do renderowania menu (poszczególne pozycje są renderowane jako elementy li listy) następującą pętlą:
{% for item in site.data.top_menu %}
<li class="nav-item">
<a class="nav-link btn-outline-primary rounded-pill px-3" href="{{ item.url }}">{{ item.name }}</a>
</li>
{% endfor %}Kolekcja danych zapisana w pliku top_menu.yaml dostępna jest w szablonie jako dane (ang. data) przypisane do strony (ang. site).
W analogiczny sposób możesz zarządzać innymi kolekcjami, np. artykułów, do których linki będą udostępniane na stronie. Jako dane możesz też zapisać, np. informacje do kontaktu (adres biura firmy, numer telefonu etc.). Generalnie warto w tej postaci zapisywać to, co może się zmieniać niezależnie od szablonu (w przypadku CMSa takie dane byłyby zapisywane w bazie danych).
Krok 7 – tworzenie szablonu podstrony i dodawanie treści
Kolejnym etapem poznawania możliwości Jekylla będzie treść strony. Na stronie głównej nie ma treści, ale są tam odnośniki do podstron. W szczególności jest odnośnik do podstrony „O nas”. Możesz ją wykonać, wykorzystując wzorzec strony z treścią dostępny w gotowym szablonie HTML/CSS.
Postępując analogicznie, jak poprzednio, umieść w katalogu _layouts plik o nazwie default.html. Plik ten należy po prostu skopiować (odpowiednio zmieniając nazwę) z szablonu HTML/CSS, z pliku work-single.html.
Warto porównać treść plików default.html i home.html. Robiąc to zauważysz, że są one bardzo do siebie podobne (zawierają wiele podobnych fragmentów). Oznacza to, że należałoby wszystkie te fragmenty przenieść do osobnych plików w katalogu _includes, a zawartość tych plików włączyć do szablonów default.html i home.html przy pomocy komendy {% include %}. Jest to niezbędne, gdyż w przypadku modyfikacji któregoś z tych fragmentów, zmiany będą od razu „widoczne” we wszystkich szablonach, w których dany fragment jest wykorzystywany. Możesz tak postąpić z sekcją head oraz ze stopką (ang. footer):
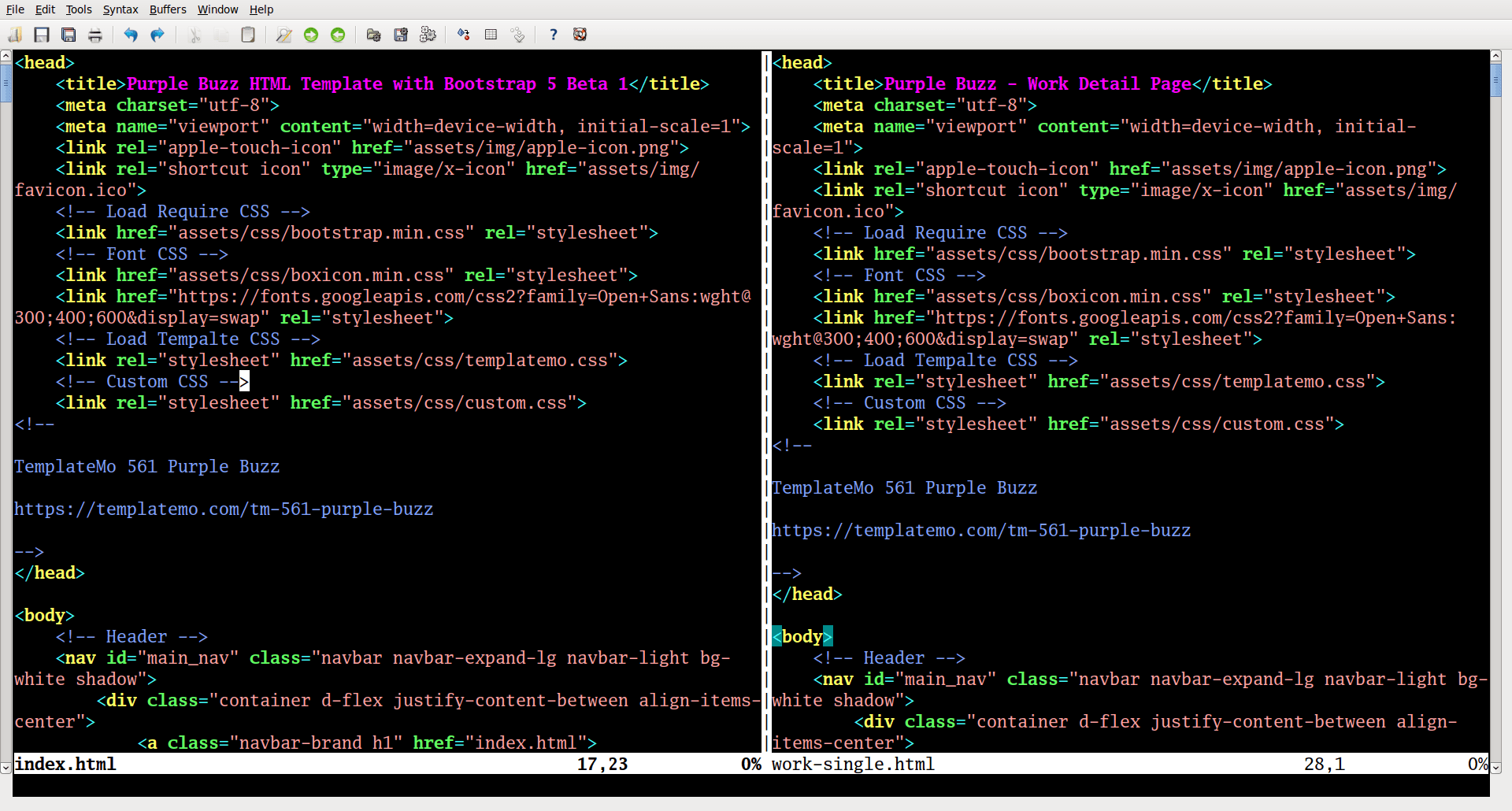
Szablon home.html, użyty na stronie głównej, nie zawierał treści. Nowy szablon ma jednak inne przeznaczenie. W pliku default.html odszukaj fragment, w którym powinna zostać umieszczona właściwa treść strony. Fragment ten zastąp prostym kodem:
{{ content }}Szablon dla strony „O nas” jest już gotowy. Pozostaje jedynie zrobić z niego użytek i utworzyć podstronę. W katalogu głównym projektu utwórz plik about.md o następującej treści:
---
layout: default
---
# O firmie
Tu jakieś informacje
Jekyll świetnie radzi sobie z plikami w formacie Markdown. Po przetworzeniu pliku about.md w katalogu _sites zostanie wygenerowany plik about.html o odpowiedniej treści:

Krok 8 – zamieszczenie plików na serwerze (deployment)
Co zrobić z wygenerowanymi plikami z katalogu _site? Aby udostępnić stronę internetową zbudowaną za pomocą Jekylla, musisz te pliki zamieścić na serwerze HTTP. W przypadku hostingów współdzielonych zazwyczaj do tego celu używany jest protokół FTP – trzeba więc skorzystać z odpowiedniego klienta (np. pod systemem Windows dostępne są WinSCP czy FileZilla, zaś pod systemami Linuksowymi FileZilla, NcFTP czy LFTP).
Podsumowanie
Po ukończeniu tego poradnika wiesz:
- Jak Jekyll traktuje pliki .html. Nie są one przetwarzane, jeśli nie zaczynają się od części początkowej.
- W jaki sposób możesz tworzyć szablony dla Jekylla. Używany jest silnik Liquid, a pliki znajdują się w katalogu _layouts.
- W jaki sposób wydzielać fragmenty z szablonów do osobnych plików zapisywanych w katalogu _includes.
- W jaki sposób tworzyć i używać kolekcje danych. Są one zapisywane w plikach w formacie YAML, w katalogu _data. W szablonach możesz się do nich odwoływać poprzez site.data.nazwa_kolekcji.
- Jak Jekyll traktuje pliki .md. Są one przetwarzane zgodnie z formatem Markdown.
Wykonanie kolejnych podstron nie będzie wymagało innej wiedzy, możesz więc śmiało ruszać do działania.
W niniejszym artykule opisano zaledwie część możliwości, jakie daje Jekyll. Są one znacznie większe i można śmiało stwierdzić, że wychodzą poza to, co jest opisane w oficjalnej dokumentacji. Nie ma, np. żadnych problemów z zamieszczeniem na stronie prostej aplikacji przeglądarkowej (tzw. SPA – ang. Single Page Application). W zasadzie nie byłoby też problemu z bardziej złożoną aplikacją. Rzecz w tym, że w sytuacji, gdy aplikacja miałaby stanowić główną treść (funkcjonalność) strony, zastosowanie Jekylla mijałoby się z celem. Jekyll (ani WordPress czy inny CMS) nie jest właściwym sposobem na udostępnianie aplikacji przeglądarkowych. Wszak nie bez powodu Jekyll jest zaliczany do tzw. generatorów stron statycznych.
Podsumowując, w każdej sytuacji należy dobrać odpowiednie narzędzie do rozwiązania problemu. Jeśli treść potrzebnej strony ma być głównie statyczna, a osoby odpowiedzialne za aktualizacje są wystarczająco kompetentne do pracy z plikami tekstowymi, z pewnością warto rozpatrzyć alternatywę dla ciężkiego WordPressa, jaką jest Jekyll.
